RTOSを使ってAI分析
はじめに
スマートフォンの普及にともなって、安価に入手できる小型のカメラが増えています。当コラムではカメラから取得したデータの表示・収集からAI分析までの開発チュートリアルを3部構成でお届けします。今回はVol.3として、RTOS「μC3/Compact」と「STM32L496G-Discovery」で、カメラからデータを取得しAIで人が映っているか否かを判別する方法をご紹介します。
概要
カメラから得られる画像データはAIによる画像認識を行うことで、画像の中に何が写っているのか認識が可能になります。一方で組み込みデバイスやモバイル端末上でAIを動かすことは、メモリや処理速度の制約やデバイス独自の実装方法が存在するため、AIと組み込み開発両方の知識が必要になります。
本チュートリアルでは、以下の画像のようにSTマイクロ社のボードを使って、カメラから取得したデータを、AIで人が写っているかどうか判別する方法を紹介します。組み込み開発未経験者でも、本チュートリアルとコードを合わせて読むことで、PoCの際に別のカメラモジュールに差し替えて使ったり、別のSTマイクロ社のボードで使う際の参考になるように考慮しています。また、文末に用語集を記述しましたので、こちらも参照ください。

必要なもの
| ボード | STM32L496G-Discovery |
| カメラモジュール | B-CAMS-OMV |
| IDE | EWARM 8.50.6 |
| RTOS, SDK | μC3/Compact for STM32L4, STM32CubeMX 6.1.2 |
| 開発PC | Windows 10 |
本チュートリアルでは、カメラとLCD,マイコンボードが必要になるため、これらが全て搭載されているマイコンボード「STM32L496G-Discovery(以後L496)」を使用します。μC3/Compact for STM32L4はhttps://www.eforce.co.jp/uc3-compact/から評価版をダウンロードすることができます。
画像認識AIの概要
1.データセットを用意して画像認識AIモデルを学習させる
2.組み込み向けにAIモデルを量子化して推論用の軽量モデルに変換する
3.STM32CubeMXでモデルをC言語のソースに変換する
4.ST社のX-CUBE-AIで用意されている関数を使って推論を実行する
上記の一連の処理を行うことで、STマイクロ社のボードを使った画像認識AIを動かすことが可能になります。
このチュートリアルのプログラムは、STM32CubeMXでDCMIやFMCなどのパラメータ設定、μC3のConfiguratorで割り込み、タスクの設定や生成したソースコードを元にして作成します。
ハードウェアの接続

LCDはL496付属のものを使用し、カメラはB-CAMS-OMVというSTマイクロエレクトロニクス社(以下STマイクロ社)の製品でOV5640というイメージセンサが載っているものを使います。
L496にはカメラ用のコネクタが付属しており、B-CAMS-OMVとFFCケーブルで簡単に接続することができます。
画像処理AIのためのデータセット作成
本チュートリアルでは、学習のためのデータセットとして80クラスのCOCOデータセットを使いますが、独自に集めた画像データセットでも学習を実行することが可能です。独自データセットを使いたい場合には、labelImgなどのツールを使用してラベルデータをCOCOと同じように作成してください。
AIの学習を行うために今回は、Google ColaboratoryのGPU環境でPythonのJupyter Notebookを使いました。Google ColaboratoryのGPUは、毎回起動時にランダムに割り当てられますが、学習時には割り当てられたNVIDIA Tesla V100を使用し、2日間ほど学習を行いました。
学習に使うCOCOデータセットは以下のコマンドをシェルで実行することで取得できます。
wget https://pjreddie.com/media/files/train2014.zip
wget https://pjreddie.com/media/files/val2014.zip
wget https://pjreddie.com/media/files/coco/labels.tgz
unzip train2014.zip
unzip val2014.zip
tar -xzvf labels.tgzダウンロードを行うとtrain2014とval2014には学習と評価で使うJPEG形式の画像ファイル、labelsには画像の中のどこに何の物体が写っているのかの正解ラベルが記述されています。
例えばCOCO_train2014_000000411913.jpgは以下の画像になりますが、COCO_train2014_000000411913.txtに記述された正解ラベルを元にOpenCVでバウンディングボックスを作成すると、以下のようになります。
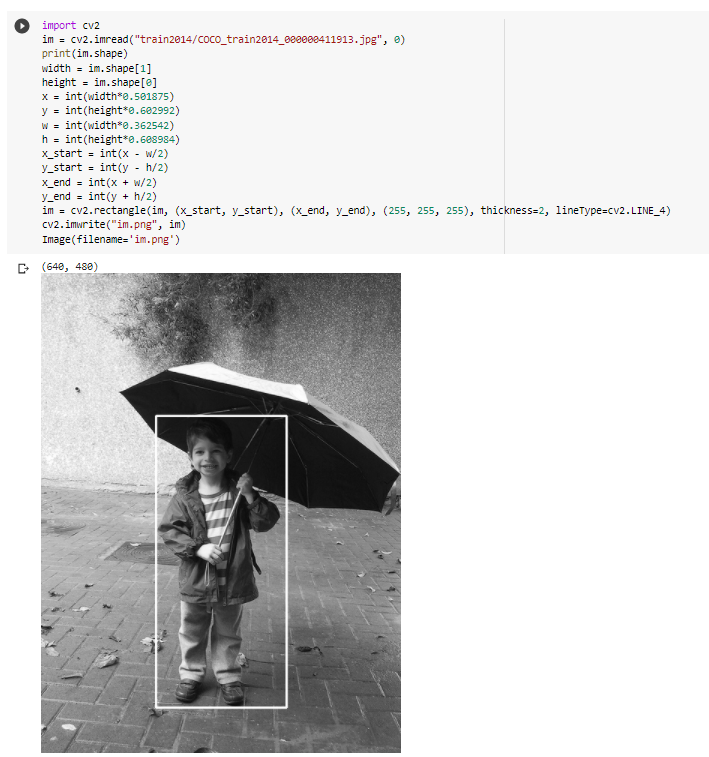
COCOデータセットは物体認識のために人や車、鳥など80種類の物体の正解ラベルが付与されており、本チュートリアルでは人を認識するために人が写っている場合を「1」、人が写っていない場合を「0」とした分類を行います。
画像処理AIモデルを学習させる
本チュートリアルでは画像認識AIモデルとしてMobileNetV2を使います。
MobileNetV2は、Googleによって開発されたモバイル端末や組み込みデバイスに向けた軽量な画像認識AIモデルとなっています。計算量の多いConvolutionの演算に対してDepth-wiseとPoint-wiseなConvolutionを用いることで計算量を削減し、軽量なモデルでも正確な画像認識を行うためにResNetでも使われているResidual Blockが採用されており、他にも様々な工夫がされています。
今回はMobileNetV2の出力層に出力ユニットを2つ用意して、人が写っている確率と人が写っていない確率をそれぞれ予想する分類問題として実装しました。
Tensorflowでは以下のように少ないコード量でMobileNetV2を実装することができます。
学習済みのweightとしてimagenetを選択し、独自に2つ出力ユニットを追加するためにinclude_top=Falseを指定してDenseを追加しています。
m0 = tf.keras.applications.mobilenet_v2.MobileNetV2(input_shape=IMG_SHAPE,
alpha=0.35,
weights='imagenet',
include_top=False)
x = GlobalAveragePooling2D()(m0.output)
x = Dropout(0.5)(x)
p = Dense(2, activation='softmax')(x)
m = tf.keras.Model(inputs=m0.input, outputs=p)
m.compile(optimizer=tf.keras.optimizers.Adam(lr=0.00002),
loss=CategoricalCrossentropy(),
metrics=['accuracy'])
画像認識AIモデルを軽量化する
学習されたAIモデルはweightとbiasというパラメータを持ちます。これらは一般的に0.3056のようにfloat型で表現されます。画像認識AIはパラメータが非常に多く、組み込みデバイスなどメモリ資源が少ない場合には量子化を行います。量子化により、weightをuint8型に変換し、少ないメモリ消費量でパラメータを持つことができます。
パラメータは一般的にhdf5もしくはsavedmodelというフォーマットで保存されますが、本チュートリアルでは学習時にhdf5で保存されたパラメータを読み込み、量子化を行います。
converter = TFLiteConverter.from_keras_model_file(KERAS_MODEL)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset
q_model = converter.convert()
KERAS_MODELには保存したhdf5フォーマットのパラメータファイルのパスを指定します。
量子化には再度データの読み込みが必要になるため、representative_datasetとして学習に使ったデータセットを指定します。
STM32CubeMXでAIをC言語のファイルに変換する
量子化した画像認識AIモデルのファイルは、.tfliteという組み込み向けのTensorflow Lite形式のファイルに変換されています。ST社のボードで扱えるようにするためには、STM32CubeMXで.tfliteファイルを変換する必要があります。
以下を実行するためには、前提としてX-CUBE-AIがSTM32CubeMXにインストールされている必要があります。インストール方法は参考文献よりSTマイクロ社が公開しているX-CUBE-AIのURLからドキュメントを参照してください。
本チュートリアルでは、mobv2_128x128x3_adam02_respin01.best_val.035.h5.uint8.tfliteという名前で保存されたtfliteファイルを以下のようにSTM32CubeMXで読み込みます。
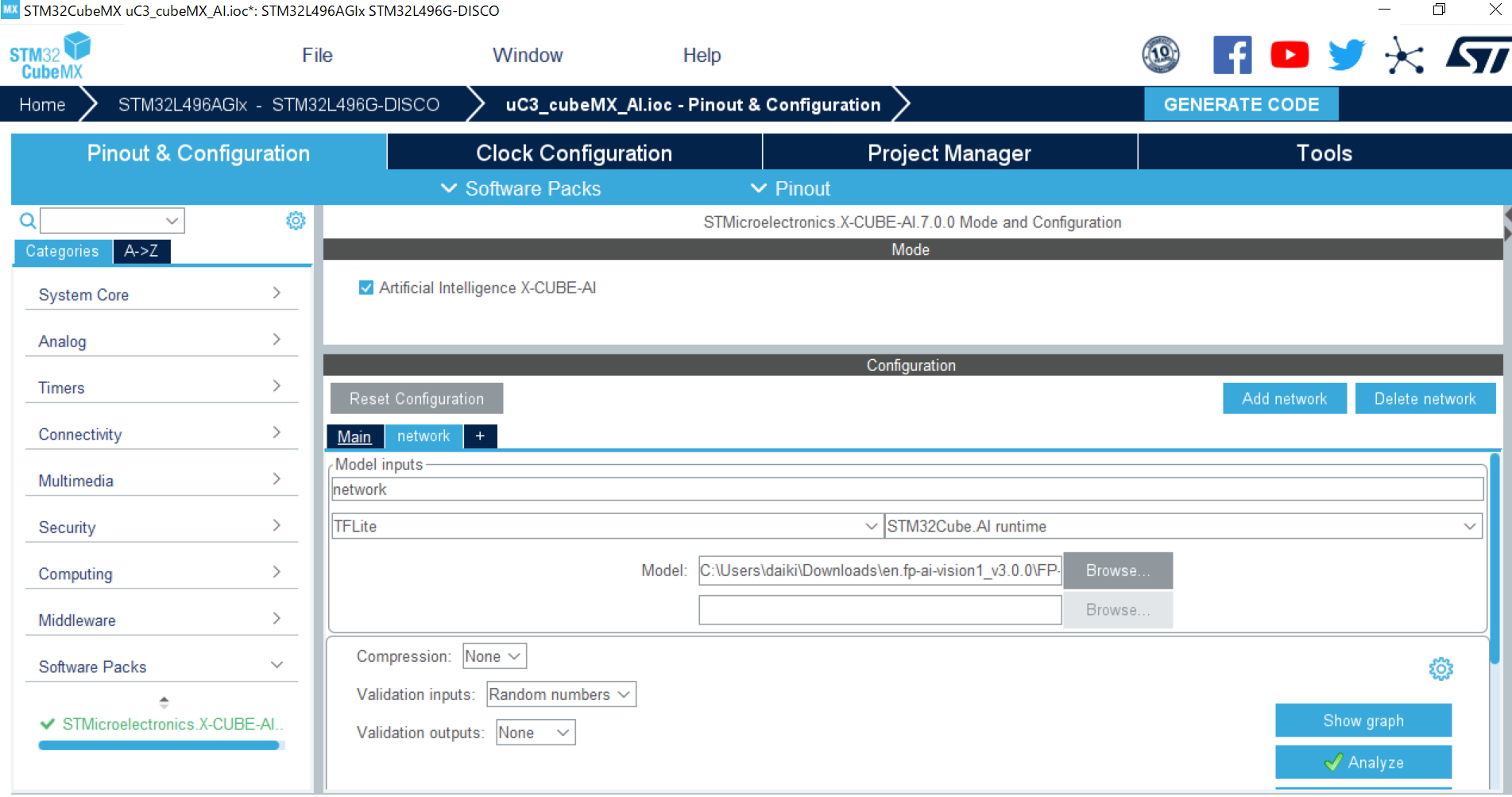
tfliteファイルを読み込んだ後にGENERATE CODEで設定関連ファイルの自動生成を行うと、network.cやnetwork.hなど、推論に必要なファイルが生成されます。
X-CUBE-AIの関数を使って推論を行う
X-CUBE-AIをenableした後にコードを自動生成すると、推論に必要なNetworkRuntime700_CM4_IAR.aというファイルが生成されます。
ドキュメントによると、上記のファイルに推論用の関数が記述されているため、画像認識AIのプロジェクトファイルには上記ファイルを含む必要があります。
AIの推論に必要な関数の使い方などは、STM32CubeMXがインストールされたフォルダ/Repository/Packs/STMicroelectronics/X-CUBE-AI/7.0.0/Documentationにまとまっています。基本的には以下の流れとなります。
/*
* Example of main loop function
*/
void main_loop()
{
/* The STM32 CRC IP clock should be enabled to use the network runtime library */
__HAL_RCC_CRC_CLK_ENABLE();
aiInit();
while (1) {
/* 1 - Acquire, pre-process and fill the input buffers */
acquire_and_process_data(in_data);
/* 2 - Call inference engine */
aiRun(in_data, out_data);
/* 3 - Post-process the predictions */
post_process(out_data);
}
}
acqire_and_process_dataでは画像データのカメラからの取得、aiRunで推論を行い、post_processではout_dataに出力される計算結果を元に結果を画面に出力する、という流れで画像認識AIをST社のボードで実現させることができました。
まとめ
まず、AIを用いて人がいる、人がいないの認識をするためには学習のための画像データセットを用意し、Tensorflowなどのフレームワークで学習を行います。
次に軽量なTensorflow Liteモデルに量子化変換を行い、生成されたtfliteファイルをSTM32CubeMXでC言語のファイルに変換を行います。
最後にX-CUBE-AIのライブラリの関数を使って、ai_initやai_runを行うことで推論が完結します。
現状の課題としてはSSDやYOLOといったObject Detectionのアルゴリズムを動作させることや、現在のFPSは0.8となっており動作がスムーズではないため、より実用的な画像認識AIを組むためには更なる改良に取り組む必要があります。
用語
STM32CubeMX
使用するボードに合わせて初期化や、ドライバのコードを自動生成するSTマイクロ社のツールです。
FPS
Frame Per Second -1秒に何枚のフレームを処理できるかというスピードの指標。一般的にスムーズな画像処理のためには最低でも2FPS以上が必要になります。
COCOデータセット
画像認識のデータセット。人や鳥、車など一般的に多く使われる物体のラベルが登録されている。SSDやYOLOといった物体認識のタスクを想定されているため、正解ラベルは画像の中の中心X座標とY座標、物体の幅と高さが登録されています。
Tensorflow
ディープラーニング用のフレームワーク。他にもCaffeやPytorchといったフレームワークがあり、基本的にどのフレームワークでもMobileNetなど有名なモデルは組むことができますが、学習のスピードや入出力のデータ形式、コードの書き方が異なります。
HDF5
学習済みAIモデルのパラメータを保存するためのファイル形式。一度学習したAIのモデルを再度他のタスクで使用するためにはweightやbiasといったパラメータを保存する必要があります。Tensorflowでは独自にsavedmodelといったフォーマットも用意されています。
Tensorflow Lite
Tensorflowなどで学習されたモデルを軽量化するフレームワーク。処理速度やメモリ制約の強いモバイル端末や組み込みデバイスでAIを動作させるためには不可欠。
MobileNetV1
Googleの開発した画像認識用の軽量AIモデル。Depth-wise ConvolutionとPoint-wise Convolutionを用いることで計算量の削減が行われている。
例えば12(width)x12(height)x3(color depth)の画像データに対して通常の5x5x3のフィルタを256枚使って畳み込み演算をすると考えると計算量は256x3x5x5x8x8=1,228,800。
MobileNetを使うとDepth-wise Convolutionで3x5x5x8x8 = 4,800、Point-wise Convolutionで256x1x1x3x8x8=49,152となり、合計で53,952。通常のConvolutionでは1,228,800となるので、相当な計算量削減効果がある。
MobileNetV2
Googleの開発したMobileNetV1の改良モデル。V1にInverted Residual BlockとLinear Bottleneckを追加した。Inverted Residual BlockではLayerをスキップしたコネクションが追加されるため、フィルタによって削減される情報量を再度獲得できると考えられます。Linear Bottleneckでは画像認識で使われるようなDeepなモデル構造ではRelu活性化によって情報が失われ過ぎてしまうと考え、Reluを使わないように変更がなされています。
参考文献
Discovery kit with STM32L496AG MCU
https://www.st.com/en/evaluation-tools/32l496gdiscovery.html
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
https://arxiv.org/abs/1704.04861
MobileNetV2: Inverted Residuals and Linear Bottlenecks
https://arxiv.org/abs/1801.04381
FP-AI-Vision1 STM32Cube function pack for high performance STM32 with artificial intelligence (AI) application for Computer Vision
https://www.st.com/en/embedded-software/fp-ai-vision1.html
X-CUBE-AI AI expansion pack for STM32CubeMX
https://www.st.com/en/embedded-software/x-cube-ai.html
A Basic Introduction to Separable Convolutions
https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
MobileNetV2: Inverted Residuals and Linear Bottlenecks
https://towardsdatascience.com/mobilenetv2-inverted-residuals-and-linear-bottlenecks-8a4362f4ffd5
labelImg: LabelImg is a graphical image annotation tool.
https://github.com/tzutalin/labelImg